
가설 검정과 통계적 추정
점추정과 구간추정
표본조사 개념
추정과 검정을 공부하기 위해서는 먼저 표본조사에 대한 개념을 이해해야 합니다.
추정과 검정이란 표본조사를 통해 얻은 데이터를 사용하여 모집단의 정보를 추정 및 검정하는 방법이기 때문입니다.
표본조사란 대상모집단의 일부 또는 전체인 표본모집단의 조건을 정의하고 표본모집단으로부터 표본을 추출하고 조사를 진행하여 표본조사 결과 얻어진 표본의 특성치인 통계량으로 대상모집단의 특성인 모수를 추정 및 검정하는 절차입니다.

점추정과 구간추정
점 추정
표본을 통해 모수를 추정할 때 추출된 표본을 이용하여 하나의 수치로 모수를 추정하는 것
ex) “고등학생의 평균 키는 여자 161cm, 남자 174cm이다.” 와 같이 수치로 표현
-평균, 표준편차, 중위수 등을 추정
-추측한 모수에 신뢰도를 나타날 수 없음
엑셀을 이용한 점추정 방법
① 엑셀의 메뉴탭에서 ‘분석도구 – 기술통계법’을 통해 구하기
② 엑셀 함수를 이용한 계산: AVERAGE, VAR, STDEV 등
ex) 고객만족도의 점추정값을 구하는 함수
구간추정(Interval estimation)
- 모수의 값이 속할 것으로 기대되는 일정한 범위를 이용하여 모수를 추정
- ex) ‘출퇴근 시간에 대한 구간추정은 40분~60분(50분±10분) ‘과 같이 수치로 표현
- 점추정은 모집단을 측정하지 않은 경우 오차가 발생할 수밖에 없음. “출퇴근 시간은 45분이다.“로 점추정하면 출퇴근시간이 46일 때 틀린 추정이 되는 것.
- 점추정의 신뢰도를 보완하기 위해 구간추정을 사용
- 모수의 추정치와 신뢰도를 함께 구할 수 있다.
- 표본의 평균과 표준오차(Standard Error of Means)를 구해서 모수의 범위를 구하는 것
- 예) 대통령의 직무 수행 긍정 평가 비율은 71%, 부정평가 비율은 21%였다.
신뢰수준 95%, 표본오차 ±3.1%포인트
- 신뢰수준=신뢰도=추정값이 존재하는 범위에 모수가 포함될 확률.
- 95%, 99%, 99.9%의 확률 중에서 조사 목적에 맞게 신뢰수준을 선택
- 신뢰수준은 주로 95%를 선택
구간 추정의 종류
-평균의 구간추정 : 고객만족도, 구매의향 등
신뢰구간
신뢰구간의 이해
- 일정한 확률 범위 내에서 모수의 값이 포함된 가능성이 있는 범위로써 상한값과 하한값으로 구간을 표시
- 표준오차를 고려하여 모집단평균 μ가 포함될 확률구간 (μ: 뮤) 고객만족도 500명 표본 조사 결과
1차: 80점
2차: 75점
-점수차이가 발생하는 이유: 표본조사를 진행하면서 발생하는 표본오차 때문.
설명: 고객만족도 점수를 파악하기 위해서 500명의 표본을 추출하여 조사한 결과 80점이 나왔다고 가정을 합니다. 그런데 이 표본의 점수가 과연 모집단인 전체 고객의 만족도 점수인가를 확인하고자 다시 500명을 추출하여 동일한 조사를 진행하니 이번에는 75점이 나왔습니다. 만약 또 다른 500명을 추출하여 동일한 조사를 진행한다고 해도 또 다른 점수가 나타날 가능성이 많습니다.
이렇게 조사를 진행할 때마다 점수가 다른 이유는 표본조사를 진행하면서 발생하는 표본오차 때문입니다.
이렇게 표본조사를 할 때마다 고객만족도 점수가 다르게 나타난다면 회사의 고객만족 관련 담당자나 경영자는 매우 혼동스러울 것입니다.
“도대체 우리 회사의 고객만족도 점수는 어느 정도인가?” 라는 의구심이 들 수밖에 없을 것입니다.
그래서 통계학에서는 모수에 대한 ‘구간추정’을 합니다.
신뢰구간의 계산
95% 신뢰수준에서의 모평균의 신뢰구간을 구하는 공식 -> 표본의 평균 ± 1.96 x (표준편차 / 표본수 )
(여기서 a½은 a의 제곱근( )을 의미합니다.) 또한 모집단의 분산을 알 수가 없기 때에 추정치인 표본의 분산으로 대체하여 사용합니다.
표본의 분산을 사용할 때 t-분포를 이용하여야 하지만 정규분포와 큰 차이가 없으므로 정규분포를 이용하여 계산하는 것이 일반적.
신뢰구간을 구할 시 신뢰수준에 따른 정규분포의 임계치
- 90% 신뢰수준에서의 신뢰구간 : 표본의 평균 ± 1.645 x (표준편차 / 표본수 )
- 95% 신뢰수준에서의 신뢰구간 : 표본의 평균 ± 1.96 x (표준편차 / 표본수 )
- 99% 신뢰수준에서의 신뢰구간 : 표본의 평균 ± 2.575 x (표준편차 / 표본수 )
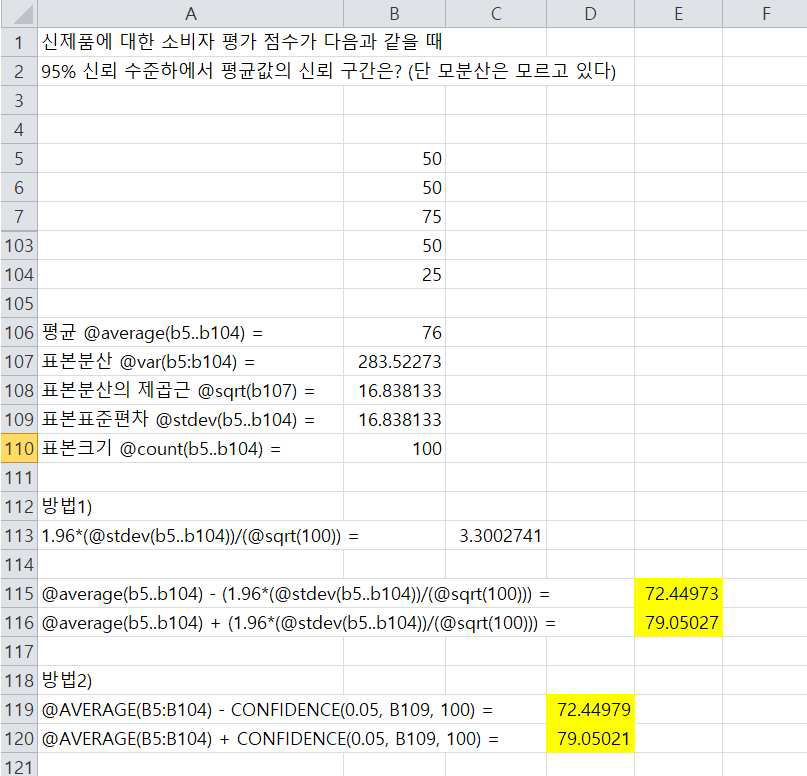
이제 실제 데이터를 이용해서 모평균의 신뢰구간을 구해보도록 하겠습니다.
그림 6-3.은 신제품에 대한 100명의 소비자에게 평가를 받은 데이터입니다.
b5셀부터 b104셀에 걸쳐 데이터가 입력되어 있습니다.
엑셀 함수로 신뢰구간 구하는 방법 1
① 표본평균, 표준편차를 계산
SQRT(값) : 절대값 구하는 함수
표본평균 : =AVERAGE(데이터범위) =AVERAGE(B5:B104) = 76
표본 표준편차 : =STDEV(데이터범위) =STDEV(B5:B104) = 16.83
② 95% 신뢰수준에서의 신뢰구간 구하는 공식에 대입
표본의 평균 ± 1.96 X (표준편차 / 표본수 )=
=AVERAGE(B5:B104) ± (1.96*(STDEV(B5:B104))/(SQRT(100))) =
76 ± 3.3002741 이므로 (76–3.30027=72.45)와 (76+3.30027=79.05)
이와 같이 각각 신뢰구간의 하한과 상한 값을 구할 수 있습니다.
엑셀 함수로 신뢰구간 구하는 방법 2
=CONFIDENCE(유의수준, 표준편차, 표본수)
95% 신뢰수준 하에서 신뢰구간을 구한다는 것은 유의수준이 5%라는 의미와도 동일합니다. 이때 다음과 같이 엑셀 함수식으로 신뢰구간을 구할 수 있습니다.
표본의 평균 ± CONFIDENCE(유의수준, 표준편차, 표본수)
=AVERAGE(B5:B104) - CONFIDENCE(0.05, B109, 100) = 72.45
=AVERAGE(B5:B104) + CONFIDENCE(0.05, B109, 100) = 79.05
엑셀에서 신뢰구간을 계산할 때는 CONFIDENCE함수를 이용하는 것이 간단하고 편리합니다.
가설 검정과 유의수준
가설 검정(hypothesis test)의 이해
대상 집단에 대하여 어떤 가설을 설정하고, 검토하는 통계적 추론.
OO 증권 고객들의 고객만족도 점수를 추정하기 위해서 표본조사를 진행한 결과 표본의 평균값이 75점이 나왔다면, 이 75점이 전체 고객의 고객만족도 평균 점수인 모평균일 것으로 추정을 하게 됩니다.
이때 이 표본의 점수인 75점이 실제 모집단의 평균 점수인지 아니면 표본의 점수일 뿐 모평균의 점수는 아니라는 가설을 설정하고 이를 일정 정도 허용오차 내에서 검정하는 것을 가설검정이라고 합니다. 이때 다음과 같은 두 개의 상반된 가설을 설정할 수 있을 것입니다.

가설1: 모집단의 고객만족도 점수가 평균 75점이다.
가설2: 모집단의 고객만족도 점수가 평균 75점이 아니다.
또는 A회사와 B회사 2개의 회사로부터 각각 500명씩 표본을 추출하여 고객만족도 조사를 한 결과 각각 70점과 80점으로 나타났다고 가정을 합시다. 그렇다면 A회사의 표본 평균 점수인 70보다 B회사의 표본 평균 점수인 80점이 높은데, 실제로 ‘A회사의 모평균인 μa < B회사의 모평균인 μb’ 인지 아니면 표본의 점수일 뿐 모평균의 점수는 차이가 없는지를 가설을 설정하고 검정을 해야 할 것입니다. 이때는 다음과 같이 2개 의 가설이 설정될 수 있을 것입니다.

이때 우리가 확인하고 싶은 것은 실제 A회사의 모집단 점수보다 B회사의 점수가 높은가를 확인하고 싶은 것입니다. 이는 A회사와 B회사의 점수 차이가 10점인데 이 10점 차이가 실제 통계적으로 유의한 차이인지 아니면 통계적으로 유의하지 않은 점수 차이인지를 확인하는 것과 같은 개념입니다. 즉, 통계적 유의성의 유무에 대한 검정이라고도 할 수 있습니다.
이처럼 확인하고 싶은 연구와 관심의 대상이 되는 가설을 ‘대립가설’이라고 하고 대립가설과 상반되는 가설을 ‘귀무가설’이라고 합니다.
H0 : 귀무가설(Null Hypothesis)
효과가 없다, 차이가 없다, 서로 다르지 않다 (반증의 대상)
H1 : 대립가설(Alternative Hypothesis)
효과가 있다, 차이가 있다, 서로 다르다 (연구의 대상)
즉, 위의 예에서 귀무가설과 대립가설은 다음과 같이 설정됩니다.

귀무가설: A회사와 B회사의 점수 차이가 없다.
대립가설: A회사와 B회사의 점수 차이가 있다.
통계적 가설에 대한 검정방법은 귀무가설을 기각할 수 있는지에 대한 확률적 확인 과정을 통해서 진행합니다.
이 사례에서 귀무가설을 기각할 수 있다면 A회사와 B회사의 모평균이 같다는 귀무가설을 기각함으로 2개 회사의 평균 점수는 실제로 차이가 난다고 결론낼 수 있는 것입니다.
즉, A회사의 점수보다 B회사의 고객만족도 모평균 점수가 실제로 높다고 판단할 수 있는 것입니다.

이렇게 귀무가설의 기각여부를 결정하기 위해서 2가지 방법을 주로 사용하는데 첫 번째는 유의확률과 유의수준을 확인하는 방법이고 두 번째는 검정통계량과 기각역을 확인하는 방법입니다.
가설 검정의 오류
가설검정 오류의 개념
-통계적 가설 검정은 모집단의 일부인 표본의 특성치인 통계량을 사용하는 과정에서 확률적 오류가 발생할 수밖에 없음.
-표본에서 나온 통계치로 모수를 추정할 때 생기는 오차
-가설검정에 있어 귀무가설의 채택/기각 중 하나를 결정할 때 오류를 범할 가능성
가설검정 오류의 종류
① 1종 오류: 귀무가설이 참(true)임에도 불구하고 귀무가설을 기각할 때 발생하는 오류
② 2종 오류: 귀무가설이 거짓(false)임에도 불구하고 귀무가설을 채택하는 오류

일반적으로 가설 검정은 제1종 오류를 중심으로 진행되는데 현재의 실험결과에 의해서 귀무가설을 기각할 때 제1종 오류를 저지를 확률을 유의확률이라 하고 제1종 오류가 발생될 최대확률을 유의수준이라고 하는데 이는 다시 말하면 연구자가 최대한 허용할 수 있는 유의확률입니다. 유의확률을 p-value(P값)이라고도 부릅니다.
표본 조사 데이터 분석결과 연구자가 설정한 유의수준 α보다 유의확률이 작으면 (1-α)x100% 신뢰수준 하에서 귀무가설을 기각할 수 있습니다.

귀무가설의 기각여부를 판단하는 다른 방법은 검정통계량과 기각역을 확인하는 방법인데 검정통계량이 기각역의 기준에 해당되면 귀무가설을 기각하는 방법이다.

예를 들면, 귀무가설 μ = 75점 vs 대립가설 : μ ≠ 75점 일 때 검정 통계량이 > 기각치 이면 귀무가설을 기각하는 방식인데 자세한 검정 방법은 7차시에서 설명하도록하겠습니다.